
Home Assistant Recorder optimieren: Datenbankgröße effizient verwalten
Bessere System-Performance und Reduzierung der Zugriffe auf SD-Karte oder SSD-Platte


Home Assistant zeichnet standardmäßig alles auf. Jeden Statuswechsel, jede Interaktion, jedes Ereignis. Die Datenbank wächst dadurch schneller, als man denkt – und das hat Folgen.
Verschleiß von Speichermedien durch Home Assistant
SSDs und SD-Karten haben eine begrenzte Anzahl an Schreibzyklen. Home Assistant läuft rund um die Uhr und schreibt kontinuierlich Daten. Das zehrt am Speichermedium. Besonders SD-Karten im Raspberry Pi sind anfällig – aber auch SSDs altern schneller, wenn die Datenbank unkontrolliert wächst.
Die unerwünschte Nebenwirkung der Datenerfassung
Die Standardkonfiguration nimmt keine Rücksicht auf Relevanz. Sensoren, die im Sekundentakt neue Werte liefern, Schalter, Leuchten – alles landet in der Datenbank. Ohne gezielte Anpassung belastet das System und Speichermedium gleichermaßen.
Kontrolle über den Recorder erlangen
Du lernst, welche Entitäten die meisten Daten produzieren, wie du die Recorder-Konfiguration gezielt anpasst und wie du anschließend alte Daten aus der Datenbank entfernst. Das Ergebnis: eine schlankere Datenbank, weniger Schreibvorgänge und ein System, das länger zuverlässig läuft.
Hast du schon einen Sensor zur Überwachung deiner Datenbankgröße?
Ich denke schon, sonst wärst du vermutlich nicht hier. Dann kannst du diesen Block gerne überspringen. Falls nicht, solltest du zuallererst einen solchen Sensor anlegen. Du brauchst ihn für Vorher-/Nachher-Vergleiche.
Sensor zur Überwachung der Datenbank-Dateigröße erstellen
Um einen Sensor in Home Assistant zu erstellen, der die Dateigröße der SQLite-Datenbank überwacht, kannst du einen benutzerdefinierten Template-Sensor verwenden. Dieser Sensor wird die Größe der home-assistant_v2.db-Datei, welche die Standarddatenbank von Home Assistant ist, regelmäßig abfragen und dir erlauben, diese Größe direkt im Home Assistant Dashboard zu verfolgen. Hier ist eine kompakte Anleitung dazu:
Schritte zur Erstellung des Sensors
- Zugriff auf die Konfigurationsdatei: Öffne die configuration.yaml-Datei deines Home Assistant-Setups. Diese Datei findest du im Hauptverzeichnis deiner Home Assistant-Installation.
- Sensor-Konfiguration hinzufügen: Füge den Code im Folgeblock zur configuration.yaml-Datei hinzu, um den Sensor zu definieren. Dieser Code erstellt einen Template-Sensor, der die Größe der SQLite-Datenbank in Megabytes (MB) misst.
Nachdem du die Konfiguration hinzugefügt hast, speichere die Datei und starte Home Assistant neu, um die Änderungen zu übernehmen. Sobald Home Assistant neu gestartet wurde, ist der neue Sensor verfügbar und kann zum Dashboard hinzugefügt werden, damit du die Dateigröße im Blick hast.
command_line:
- sensor:
name: DB Size
unique_id: filesize_db
command: "du -m /config/home-assistant_v2.db | cut -f1"
unit_of_measurement: 'MB'
scan_interval: 900
scan_interval ist hier auf 15 Minuten eingestellt
Verlierst du deine Langzeitstatistiken?
Beim Ausschließen und Purgen kommt schnell die Sorge auf. Du wirfst Daten weg – gehen damit auch deine Verlaufsdaten verloren?
Nein. Deine Messsensoren behalten ihre Langzeithistorie. Ganz automatisch. Egal ob Stromverbrauch, Temperatur oder Luftfeuchte.
Der Grund: Home Assistant führt zwei getrennte Speicher. Der Recorder hält die Detaildaten – jeden einzelnen Messwert. Standardmäßig zehn Tage. Danach werden sie gelöscht.
Parallel laufen die Long-Term Statistics. Sie speichern deine Messsensoren dauerhaft. Stündlich gemittelt, nicht in voller Auflösung. Genau davon leben dein Energy-Dashboard und die Langzeit-Graphen. Kilowattstunden, Temperaturverläufe, Verbrauchswerte – alles bleibt erhalten. Auch nach den zehn Tagen. Auch wenn der Recorder die Sekunden-Details längst verworfen hat.
Technisch hängt das an der state_class. Sensoren mit measurement, total oder total_increasing wandern in die Langzeitstatistik. Bei den gängigen Energie-, Temperatur- und Feuchtesensoren ist dieser Wert vom Hersteller korrekt gesetzt. Du musst dafür nichts tun.
Detaildaten kürzen kostet dich also nicht die Historie, die wirklich zählt.
Anpassung der Recorder-Einstellungen für eine schlanke Home Assistant Datenbank
Home Assistant bietet dir die Möglichkeit, durch eine angepasste Konfiguration des Recorders gezielt bestimmte Geräte und Entitäten von der Datenaufzeichnung auszuschließen. Diese Funktionalität ist besonders wertvoll, da sie dir erlaubt, die Kontrolle über die Menge und Art der gespeicherten Daten zu behalten. Indem du selektiv festlegst, welche Informationen für dich von Bedeutung sind und aufgezeichnet werden sollen, kannst du eine Überlastung der Datenbank vermeiden und gleichzeitig die Systemperformance und die Lebensdauer deiner Speichermedien schonen. Die Konfiguration des Rekorders erfolgt über die configuration.yaml, über die du sicher schon gestolpert bist.
Tipp: Auslagern der Recorder-Konfiguration
Die Recorder-Konfiguration direkt in der configuration.yaml Datei vorzunehmen, kann auf lange Sicht unübersichtlich werden, besonders wenn du viele Anpassungen vornimmst. Um deine Konfiguration übersichtlich und wartbar zu halten, ist es sinnvoll, die Recorder-Einstellungen in eine eigene YAML-Datei auszulagern. Dies erleichtert nicht nur die Verwaltung deiner Einstellungen, sondern macht auch das Experimentieren mit verschiedenen Konfigurationen einfacher, ohne das Risiko, die Hauptkonfigurationsdatei zu überladen oder versehentlich Fehler einzuführen.
Schritte zur Auslagerung der Recorder-Konfiguration
- Erstelle eine neue YAML-Datei für die Recorder-Konfiguration, z.B. recorder.yaml im gleichen Verzeichnis wie deine configuration.yaml.
- Definiere deine Recorder-Einstellungen in der recorder.yaml. Hier kannst du festlegen, welche Entitäten und Ereignisse aufgezeichnet oder ignoriert werden sollen. Die Entscheidung, bestimmte Daten nicht zu erfassen, sollte auf der Häufigkeit der Zustandsänderungen und der Relevanz der Informationen basieren.
- Binde die recorder.yaml in deine Hauptkonfiguration ein. Dies erfolgt durch einen Verweis in der configuration.yaml Datei:
recorder: !include recorder.yaml
Dieser Eintrag weist Home Assistant an, die Konfiguration für den Recorder-Dienst aus der angegebenen Datei zu laden. Ich habe für eine gute Übersicht alle meine Verweise auf inkludierte Files ganz oben in der configuration.yaml platziert
Warum eine selektive Datenaufzeichnung sinnvoll ist
Durch das bewusste Auswählen, welche Daten aufgezeichnet werden, kannst du sicherstellen, dass nur relevante Informationen gespeichert werden. Dies ist besonders wichtig für Geräte, die häufig ihren Status ändern, wie Sensoren oder Schalter. Eine unnötig große Datenbank belastet nicht nur den Speicher deines Systems, sondern kann auch die Analyse der aufgezeichneten Daten erschweren.
Die Auslagerung und gezielte Konfiguration des Recorder-Dienstes trägt zu einem effizienteren und leistungsfähigeren Home Assistant System bei. So bleibt mehr Ressourcen für die eigentlichen Automatisierungen und die schnelle Reaktion deines Smart Homes auf deine Bedürfnisse.
Übersicht: Was muss, was sollte ich tracken, was besser nicht?
Die folgende Tabelle hilft dabei, eine erste Einschätzung für dein System und vorzunehmen. Hilfreich vor allem, wenn man ein System neu aufsetzt.
Sollte dein Home Assistant schon eine Weile Daten sammeln: Du gehst es besser gezielt an im Abschnitt Ermittlung der datenintensiven Entitäten.
| Entitätstyp | Aufzeichnen? | Begründung |
|---|---|---|
| Temperatursensor (innen/außen) | ✅ Ja | Historische Verläufe für Auswertungen sinnvoll |
| Luftfeuchtigkeitssensor | ❌ Nein | Aktueller Wert reicht für Automationen; Verlaufsauswertung ist Sonderfall |
| Bewegungsmelder (PIR) | ⚠️ Optional | Geringe Schreibrate in Räumen; in stark frequentierten Bereichen ggf. ausschließen |
| Präsenzsensor (z. B. mmWave) | ❌ Nein | Sehr hohe Zustandswechselrate, kein historischer Bedarf |
| Energiemessung (kWh gesamt) | ✅ Ja | Wichtig für Verbrauchsauswertungen und Langzeitstatistiken |
| Energiemessung (Echtzeit-Watt) | ❌ Nein | Hohe Schreibrate; Langzeitstatistiken entstehen automatisch über Long-term Statistics |
| Lichtschalter / Dimmer (Status) | ⚠️ Optional | Nur bei aktiver Auswertung oder Automationsdiagnose relevant |
| Schalter (an/aus) | ⚠️ Optional | Abhängig vom Anwendungsfall |
| Binärsensor (Tür/Fenster offen/zu) | ⚠️ Optional | Sinnvoll bei Sicherheits- oder Lüftungsauswertungen |
| Helligkeitssensor (lux) | ❌ Nein | Ändert sich sehr häufig; aktueller Wert für Automationen ausreichend |
| Datenbankgrößen-Sensor | ❌ Nein | Meta-Sensor ohne historischen Mehrwert |
| System-Sensoren (CPU, RAM, Last Boot) | ❌ Nein | Hohe Frequenz; aktueller Wert genügt im laufenden Betrieb |
| Wetter-Entitäten | ❌ Nein | Viele Attribute, häufige Updates, kein Mehrwert gegenüber externen Wetterdiensten |
| Personen / Device Tracker | ⚠️ Optional | Für Automationen reicht der aktuelle Zustand; Aufzeichnung speichert Bewegungsprofile – Datenschutz abwägen |
| Input-Helfer (input_boolean, input_number etc.) | ✅ Ja | Steuern Automationen; Zustandshistorie sinnvoll |
| Media Player (Status) | ⚠️ Optional | Nur wenn Abspielhistorie oder Nutzungsauswertung gewünscht |
| Kalender-Entitäten | ❌ Nein | Kein Mehrwert in der Datenbank |
| Update-Entitäten | ❌ Nein | Zustand hat keinen historischen Wert |
Ermittlung der datenintensiven Entitäten
Um die Leistung von Home Assistant zu optimieren und die Belastung der Speichermedien zu reduzieren, ist es entscheidend zu wissen, welche Entitäten die meisten Daten produzieren. Für die Standard-Datenbank von Home Assistant, die SQLite verwendet, bietet das Add-on „SQLite Web“ eine benutzerfreundliche Oberfläche, um solche Analysen durchzuführen. Falls du eine andere DB benutzt, musst du dich auf die Suche nach einem dazu passenden Add-On machen. Mit SQL-Abfragen kannst du gezielt ermitteln, welche Entitäten für das Anschwellen der Datenbankgröße verantwortlich sind.
Nutzung von SQLite Web für SQL-Abfragen
Nach der Installation des SQLite Web Add-ons kannst du über die Home Assistant Benutzeroberfläche darauf zugreifen. Das Add-on ermöglicht es dir, SQL-Abfragen direkt auszuführen, um detaillierte Informationen über die Datenverwendung durch verschiedene Entitäten zu erhalten.
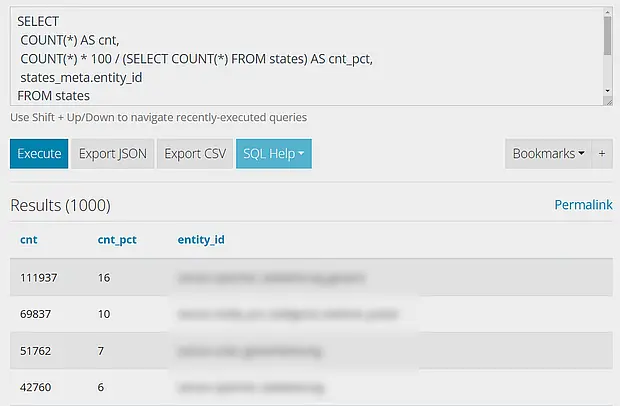
Gib dazu einfach folgende DB-Query im Feld “Query” auf der Startseite des SQLite Web Addons ein und klicke auf “Execute”:
SELECT COUNT(*) AS cnt, COUNT(*) * 100 / (SELECT COUNT(*) FROM states) AS cnt_pct, states_meta.entity_id FROM states INNER JOIN states_meta ON states.metadata_id = states_meta.metadata_id GROUP BY states_meta.entity_id ORDER BY cnt DESC
Diese Abfrage gibt dir einen Überblick über alle Entitäten, sortiert nach der Anzahl ihrer Einträge in der Datenbank, beginnend mit den datenintensivsten. Mit diesen Informationen kannst du gezielt Entscheidungen treffen, welche Daten für dich wirklich von Bedeutung sind.
Entscheidungsfindung für die Datenaufzeichnung
Mit den Ergebnissen der SQL-Abfragen in der Hand musst du entscheiden, welche Entitäten weiterhin aufgezeichnet werden sollen. Einige Entitäten, wie Temperatursensoren oder Bewegungsmelder, können sehr datenintensiv sein, da sie regelmäßig ihren Status aktualisieren. Frage dich, ob du die historischen Daten jeder dieser Entitäten benötigst. In vielen Fällen wirst du feststellen, dass eine Reduzierung der aufgezeichneten Entitäten möglich ist, ohne die Funktionalität deines Smart Homes einzuschränken.
Basierend auf deiner Entscheidung passt du dann die Recorder-Einstellungen in Home Assistant an, um nur noch relevante Daten aufzuzeichnen.
Fun fact: Wenn du deinen Sensor mit der Dateigröße frisch angelegt hat, taucht er hier noch nicht auf - du solltest ihn dennoch zu den excludes hinzufügen!
Optimierung der Recorder-Konfiguration in Home Assistant
Jetzt solltest Du schon wissen, welche Entities weiter getrackt oder nicht mehr aufgezeichnet werden sollen. Die Recorder-Konfiguration bietet dafür verschiedene clevere Optionen. Diese erlauben es dir, gezielt zu steuern, welche Daten aufgezeichnet werden und wie lange sie gespeichert bleiben. Hier ein Überblick über die Schlüsselelemente:
Includes und Excludes
- Includes: Bestimme genau, welche entities, domains oder event_types aufgezeichnet werden sollen. Dies ermöglicht eine fokussierte Datenerfassung, bei der nur die für dich wichtigen Informationen gespeichert werden.
- Excludes: Hier legst du fest, welche Daten explizit nicht aufgezeichnet werden sollen. Dies ist nützlich, um datenintensive Entitäten oder Domains auszuschließen, die die Datenbank unnötig aufblähen.
Domains
- Domains: Bezieht sich auf die übergeordneten Kategorien von Entitäten wie light, sensor oder switch. Durch das Inkludieren oder Exkludieren ganzer Domains kannst du die Datenaufzeichnung auf einer breiteren Ebene steuern.
Event_Types
- Event_Types: Bestimmt, welche Arten von Ereignissen (z.B. state_changed, call_service) aufgezeichnet werden. Dies hilft dir, nur relevante Ereignisse zu speichern und irrelevante zu ignorieren.
Wildcards und Entity_Globs
- Entity_Globs: Ermöglichen eine flexiblere Angabe von Entitäten durch Mustererkennung (z.B. sensor.temperature_*). Das ist besonders hilfreich, wenn du mehrere ähnliche Entitäten gleichzeitig steuern möchtest.
Purge_Days
- Purge_Days: Legt fest, wie viele Tage die aufgezeichneten Daten gespeichert bleiben, bevor sie automatisch gelöscht werden. Dies trägt dazu bei, die Datenbankgröße im Zaum zu halten und sicherzustellen, dass nur aktuelle Daten aufbewahrt werden.
Commit_Interval
- Commit_Interval: Legt fest, wie oft der Recorder Änderungen bündelt und aufs Speichermedium schreibt. Der Standardwert liegt bei 5 Sekunden. Ein höherer Wert wie 30 reduziert die Schreibvorgänge und schont vor allem SD-Karten. Die Aufzeichnung hängt dann bis zu 30 Sekunden hinterher – in der Praxis irrelevant, weil deine Automationen weiter in Echtzeit laufen.
Durch die Kombination dieser Optionen kannst du eine maßgeschneiderte Recorder-Konfiguration erstellen, die perfekt auf die Bedürfnisse deines Smart Homes abgestimmt ist. Hier ein Beispiel, das zeigt, wie all diese Optionen in deiner YAML-Konfigurationsdatei verwendet werden können:
recorder:
purge_keep_days: 10
commit_interval: 30
include:
domains:
- light
- switch
entities:
- sensor.temperature_kitchen
event_types:
- call_service
exclude:
domains:
- sensor
entities:
- sensor.humidity_bathroom
event_types:
- service_executed
entity_globs:
- sensor.temperature_*
- sensor.shelly*_power
In diesem Beispiel werden Daten von Lichtern und Schaltern sowie spezifische Temperatursensoren aufgezeichnet und für 10 Tage gespeichert. Gleichzeitig werden alle Sensoren (außer dem ausdrücklich inkludierten), bestimmte feuchtigkeitssensitive Sensoren und temporäre Backup-Temperatursensoren von der Aufzeichnung ausgeschlossen. Zusätzlich werden bestimmte Ereignistypen nicht aufgezeichnet, um die Datenmenge weiter zu reduzieren.
Durch die Verwendung von entity_globs und Wildcards kannst du effektiv Muster für die Inklusion oder Exklusion spezifischer Entitäten definieren, was die Konfiguration des Recorders deutlich flexibler und leistungsfähiger macht.
Strategien für die Verwendung von Include und Exclude
- Fokussierte Aufzeichnung mit Include: Wenn du dich auf include festlegst, legst du einen spezifischen Rahmen fest, innerhalb dessen Daten aufgezeichnet werden. Alles, was nicht explizit aufgeführt ist, wird von der Aufzeichnung ausgeschlossen. Dies ist besonders nützlich, wenn du nur an einem eng definierten Datenset interessiert bist.
- Breite Aufzeichnung mit Exclude: Die Verwendung von exclude ermöglicht eine breitere Datenerfassung, wobei du spezifische Entitäten, Domains oder Ereignistypen ausschließen kannst. Dies eignet sich, wenn du grundsätzlich viele Daten erfassen, aber bestimmte datenintensive oder irrelevante Informationen ausschließen möchtest.
Kombination von Include und Exclude
Die Kombination beider Ansätze erlaubt eine sehr detaillierte Kontrolle über die Datenaufzeichnung. Du kannst z.B. mit exclude breitflächig Domains ausschließen, um dann mit include bestimmte Entitäten aus diesen Domains gezielt wieder zur Aufzeichnung freizugeben.
Beispiel:
Du möchtest generell keine Sensordaten aufzeichnen, außer die von bestimmten Temperatursensoren. Hierfür schließt du die sensor-Domain aus und beziehst die spezifischen Sensoren über include wieder ein.
recorder:
exclude:
domains:
- sensor
include:
entities:
- sensor.temperature_kitchen
Wichtiger Hinweis: Wenn Einträge sowohl in include als auch in exclude vorhanden sind, hat include Priorität. Das bedeutet, dass Entitäten, die unter include aufgeführt sind, aufgezeichnet werden, selbst wenn ihre Domains oder sie selbst auch unter exclude gelistet sind.
Bei Bedarf findest Du weitere Infos in der Home Assistant Dokumentation.
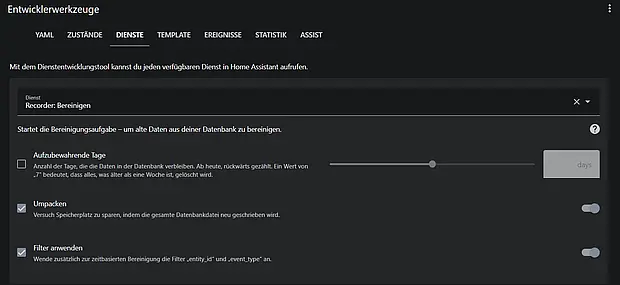
Recorder-Dienst zur Datenbankbereinigung in den Entwicklerwerkzeugen ausführen
Der Recorder-Dienst recorder.purge kann über die Entwicklerwerkzeuge aufgerufen werden, um alte Daten zu entfernen. Hier zeige ich dir, wie du vorgehen musst.
Vorsicht: In diesem Schritt werden deine Einstellungen aus der recorder.yaml angewendet. Hast du dort Entities von der Aufzeichnung ausgeschlossen, werden nicht nur keine neuen Daten aufgezeichnet, sondern auch alle alten Daten gelöscht. Es empfiehlt sich, vor der Ausführung ein volles Backup von Home Assistant zu machen (Einstellungen → System → Backups).
Schritte zur Ausführung des Recorder-Purge-Dienstes
- Navigiere zu den Entwicklerwerkzeugen: Im Home Assistant Dashboard findest du im Seitenmenü den Punkt „Entwicklerwerkzeuge“. Klicke darauf, um zu den verschiedenen Optionen für Entwickler zu gelangen.
- Dienste aufrufen: Innerhalb der Entwicklerwerkzeuge gibt es einen Tab mit der Bezeichnung „Dienste“. Dieser Bereich ermöglicht es dir, verschiedene Dienste innerhalb von Home Assistant auszuführen.
- Recorder-Purge-Dienst auswählen: In der Liste der verfügbaren Dienste suche nach recorder.purge bzw. Rekorder:Bereingen. Dieser Dienst ist dafür verantwortlich, alte Daten aus der Datenbank zu entfernen.
- Dienstdaten konfigurieren: Um den recorder.purge Dienst auszuführen, musst du spezifische Dienstdaten angeben. Hierbei sind die Optionen keep_days, repack, und apply_filter von besonderer Bedeutung.
- keep_days: Definiert die Anzahl der Tage, für die Daten in der Datenbank behalten werden sollen. Alle Daten, die älter sind, werden gelöscht. Das kannst Du für unseren Zweck wie in der Voreinstellung belassen.
- repack: Wenn auf true gesetzt, komprimiert Home Assistant die Datenbank nach der Bereinigung, um freien Speicherplatz zurückzugewinnen. Dies dient dazu, die Datenbankgröße zu reduzieren, wenn Daten gelöscht werden und muss in unserem Fall gesetzt werden.
- apply_filter: Muss auf true gesetzt werden, damit Filter, die in der Recorder-Konfiguration definiert wurden, angewendet werden.
Nachdem du die Daten eingegeben hast, klicke auf „Dienst aufrufen“, um den Prozess zu starten. Der Purge-Vorgang kann je nach Größe der Datenbank und der Leistung deines Systems einige Zeit in Anspruch nehmen. Nach Abschluss der Bereinigung solltest du eine merkliche Verbesserung der Systemleistung und eine Verringerung der belegten Speichergröße feststellen.
Fazit:
Durch die gezielte Konfiguration des Home Assistant Recorders hast du nicht nur die Datenbankgröße reduziert und die Systemperformance verbessert, sondern schonst auch deine SSDs und/oder SD-Karten durch die Verringerung unnötiger Schreibvorgänge. Denke daran, dass die Integration neuer Geräte höchstwahrscheinlich ein Nacharbeiten erfordert. Es schadet nicht, von Zeit zu Zeit ein Auge auf die DB-Größe zu haben und ggf. die DB-Abfrage erneut durchzuführen. Und bei Bedarf deine Konfiguration anzupassen.
Quellen
- Recorder – Home Assistant Dokumentation: Konfiguration von commit_interval, purge_keep_days, auto_purge, include/exclude, Domains, Entity-Globs und Event-Types. Enthält den offiziellen Hinweis zum SD-Karten-Verschleiß sowie die Aktion recorder.purge mit keep_days, repack und apply_filter.
- History – Home Assistant Dokumentation: Zusammenspiel von Recorder und History, Standard-Aufbewahrung von zehn Tagen und Übergang zu den Langzeitstatistiken.
- Long- and short-term statistics – Home Assistant Data Science Portal: Dauerhafte, stündlich gemittelte Speicherung für Sensoren mit state_class measurement, total oder total_increasing. Die Langzeitstatistik-Tabelle wird nie geleert.
- Command Line – Home Assistant Dokumentation: Grundlage für den command_line-Sensor zur Überwachung der Datenbank-Dateigröße.
Schlechtes Gefühl, weil Du eine SD-Karte benutzt?
Die Samsung PRO Endurance microSD-Karte* ist speziell für dauerhafte Schreib- und Lesevorgänge optimiert und bietet eine deutlich höhere Lebensdauer als herkömmliche microSD-Karten. Da Home Assistant kontinuierlich Daten schreibt (z. B. Log-Dateien, Sensorwerte), reduziert die hohe Schreibresistenz das Risiko von Speicherfehlern und frühzeitigem Ausfall erheblich. Damit erreichst Du was Ausfallsicherheit und Geschwindigkeit betreffend nicht das Niveau einer SSD, bekommst aber eine deutlich verbesserte Lebenserwartung gegenüber Standard-SD-Karten zu Bruchteil des Preises, der für eine SSD-Platte aufgerufen wird.